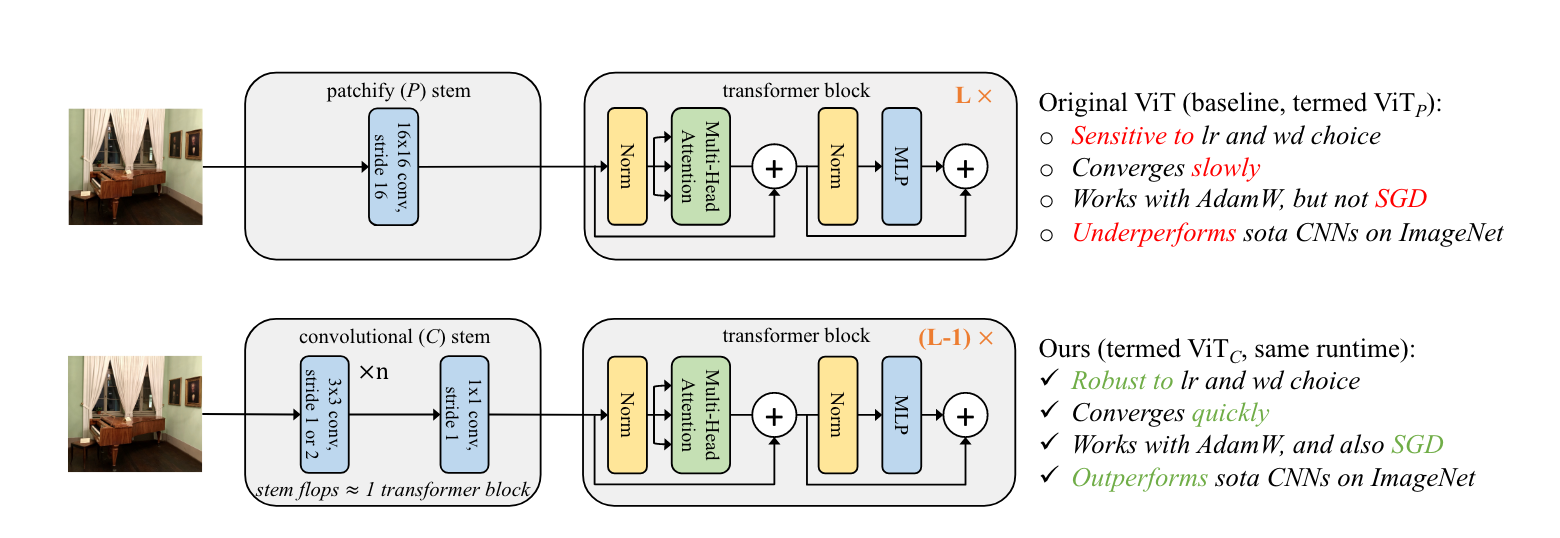
Hypothesis
ViT’s patchify convolution is contrary to standard early layers in CNNs. Maybe that’s the cause?
Main idea
Replace patchify convolution with a small number of convolutional layers and drop one transformer block to make comparison fair.
Notes for myself:
- Interesting experimentation regarding optimizability , maybe take into account into hessian analysis