in between the backbone layers
- Multi-View Foundation Models
- Exploring Temporally-Aware Features for Point Tracking (technically not video, but related)
after the backbone layers
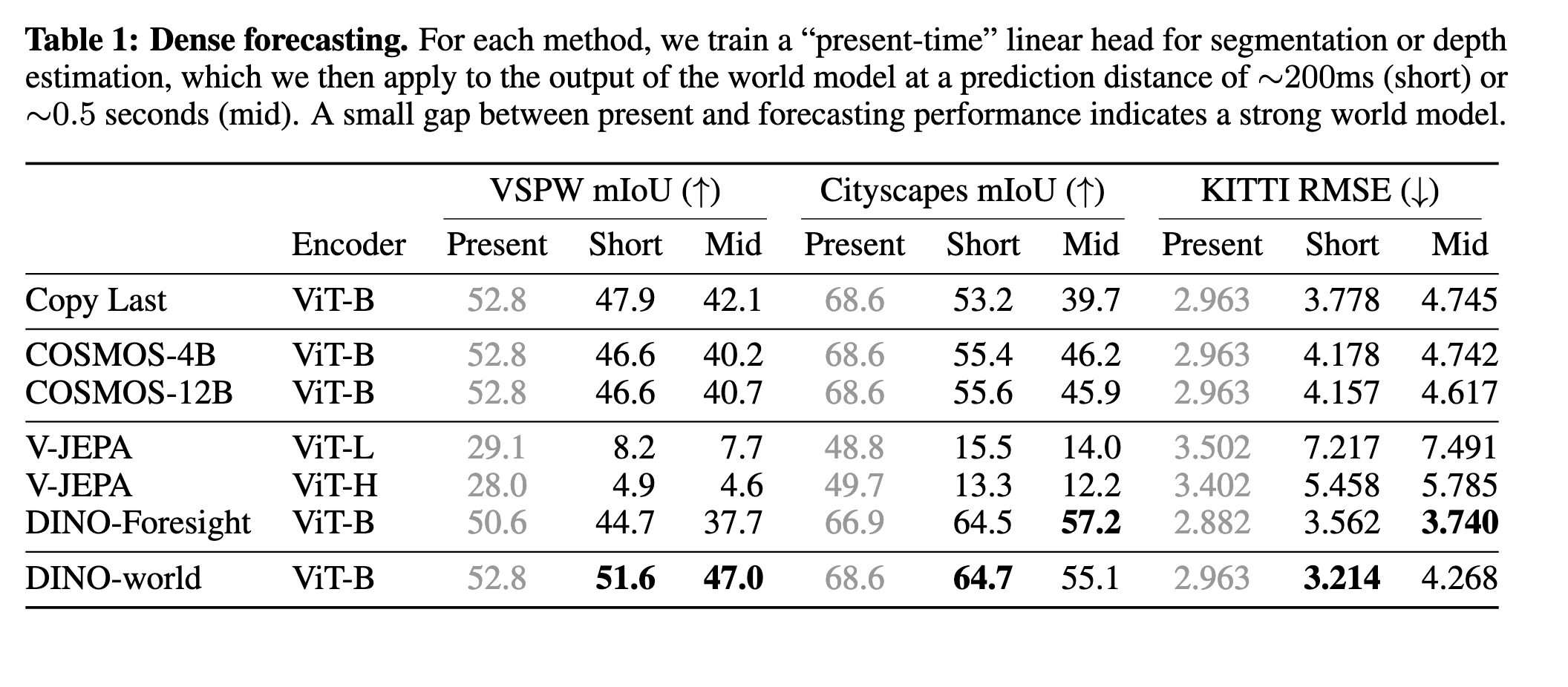
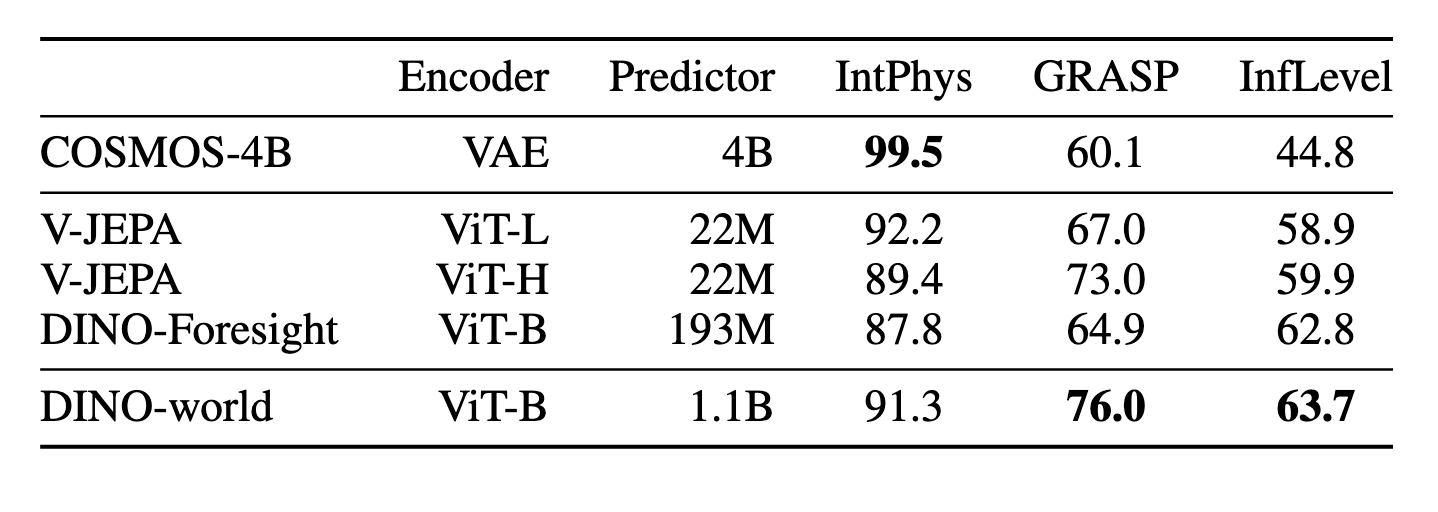
DINOv2/DINOv3 features does incredibly well on video tasks (video classification, dense forecasting, intuitive physics).
From DINOv3.
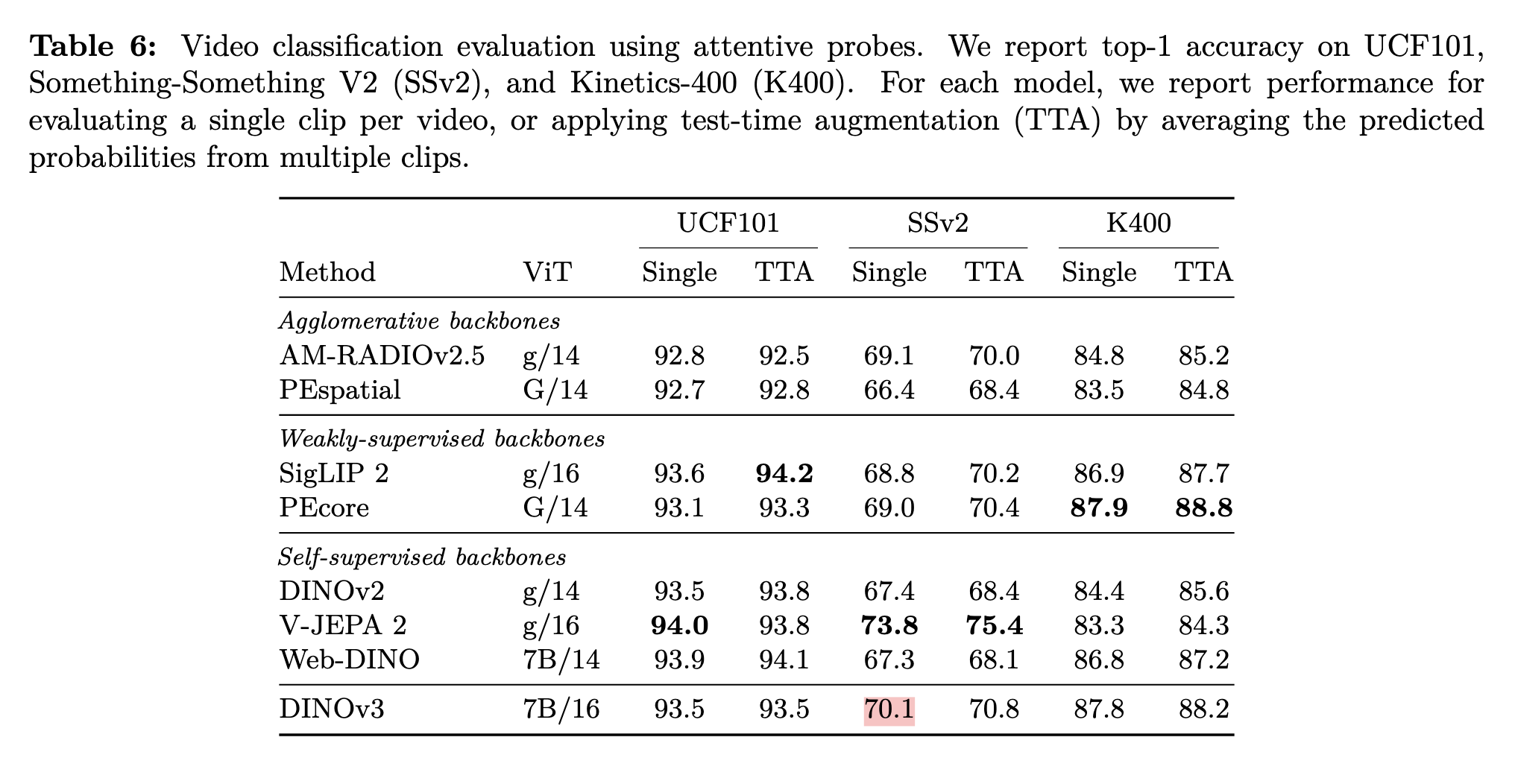
From Back to the Features - DINO as a Foundation for Video World Models