Abstract
We present DINO-world, a powerful generalist video world model trained to predict future frames in the latent space of DINOv2. By leveraging a pre-trained image encoder and training a future predictor on a large-scale uncurated video dataset, DINO-world learns the temporal dynamics of diverse scenes, from driving and indoor scenes to simulated environments. We show that DINO-world outperforms previous models on a variety of video prediction benchmarks, e.g. segmentation and depth forecasting, and demonstrates strong understanding of intuitive physics. Furthermore, we show that it is possible to fine-tune the predictor on observationaction trajectories. The resulting action-conditioned world model can be used for planning by simulating candidate trajectories in latent space.
Notes
Summary
Objective: Future frame prediction in latent space Encoder: DINOv2 image encoder (frozen) Predictor: Cross-Attention ViT-G: each future patch attends to all patch tokens from all past timestamps
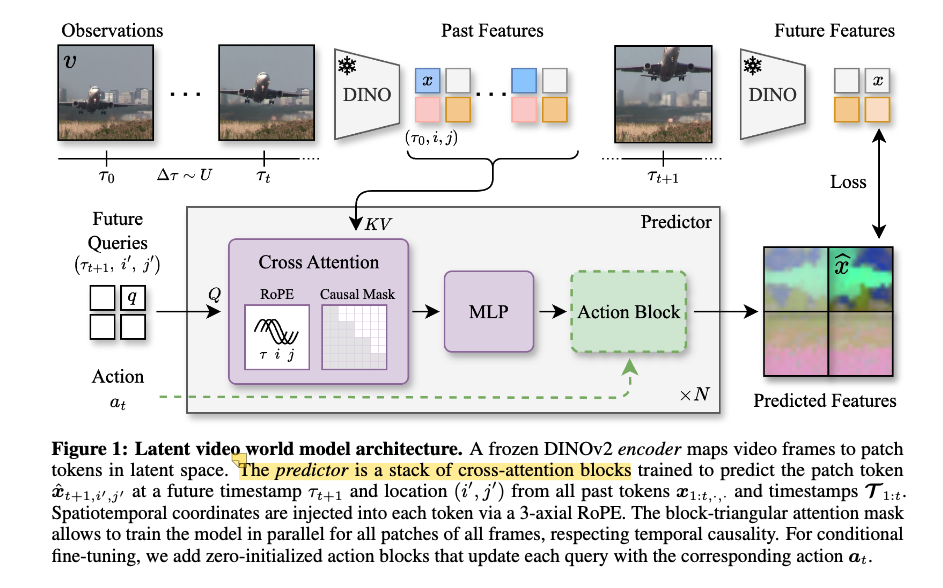
Somewhat interesting implementation details:
- This is not masked prediction like V-JEPA, this is future frame latent prediction.
- The predictor is a cross-encoder, like CAPI, not like VideoMAE/SIGMA. (This is well visualized in CAPI’s Figure 5)
- In MAE/VideoMAE/SIGMA we feed both the visible tokens and the masked tokens to the decoder (self-attention).
- In CAPI/DINO-world, the predictor does not have self-attention layers, each future spatio-temporal token (mask + pos_embed) attends only to the visible tokens from the past via cross-attention.
- It is trained with
(num_frames), which seems low compared to other foundation models that operate on videos.